Web Browser: Rendering Paths, JS Engines, and Performance Tweaks
Critical Rendering Path, Speculative Parsing, Render Blocking Resources, and Structure of Web Browsers.

The Web Browser is inarguably the most common portal for users to access the web. The advancement of web browsers (through the series of history) has led many traditional “thick clients” to be replaced by browsers enhancing their usability and ubiquity.
The web browser is an application that provides access to the web server, sends a network request to the URL, obtains resources, and interactively represents them. Common Browsers today include Firefox, Google Chrome, Safari, Internet Explorer, and Opera.
Structure of Web Browser
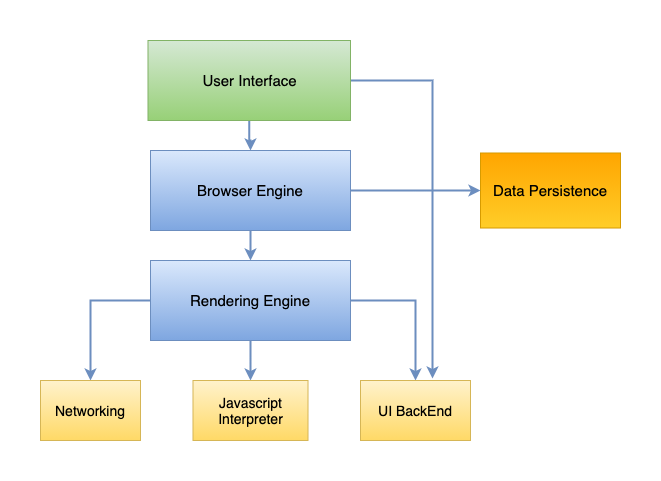
1. User Interface
It is a space where interaction between the user and the browser (application) occurs via the control presented in the browser. No specific standards are imposed on how web browsers should look and feel. The HTML5 specification does not define specific UI elements but references common components such as the location bar, personal bar, scrollbars, status bar, and toolbar.
2. Browser Engine
It provides a high-level interface between UI and the underlying rendering engine. It makes a query and manipulates the rendering engine based on the user interaction. It provides a method to initiate loading the URL and takes care of reloading, back, and forward browsing actions.
3. Rendering Engine
The Rendering Engine is responsible for displaying the content of the web page on the screen. The primary operation of a Rendering engine is to parse HTML. By default, it displays HTML, XML, and images and supports other data types via plugin or extension.

Rendering Engine for modern web Browsers
- Firefox — Gecko Software
- Safari — WebKit
- Chrome, Opera (15 onwards) — Blink
- Internet Explorer — Trident
Critical Rendering Path
To plot the pixels in the screen (first render), the browser after receiving the data (HTML, CSS, JavaScript) from the network has to go through a series of processes/techniques called Critical Rendering Path. This includes DOM, CSSOM, Render Tree, Layout, and Painting.
Data to DOM
The requested content from the networking layer is received in the rendering engine (8 kb chunks generally) in the binary stream format. The raw bytes are then converted to a character (based upon character encoding) of the HTML file.
Characters are then converted into tokens. Lexer carries out lexical analysis, breaking input into tokens. During tokenization, every start and end tag in the file is accounted for. It knows how to strip out irrelevant characters like white space and line breaks. The parser then carries out syntax analysis, applying the language syntax rule to construct a parse tree by analyzing the document structure.
The parsing process is iterative. It will ask the lexer for a new token and the token will be added to the parse tree if the language syntax rule matches. The parser will then ask for another token. If no rule matches, the parser will store the token internally and keep asking for tokens until a rule matching all the internally stored tokens is found. If no rule is found, then the parser will raise the exception. This means the document was not valid and contained syntax errors.
These nodes are linked in the tree data structure called DOM (Document Object Model) which establishes the parent-child relationship, and adjacent sibling relationships.

CSS Data to CSSOM
Raw bytes of CSS data are converted into characters, tokens, nodes, and finally in CSSOM (CSS Object Model). CSS has something called cascade which determines what styles are applied to the element. Styling data to the element can come from parents (via inheritance) or are set to the elements themselves. The browser has to recursively go through the CSS tree structure and determine the style of the particular element.
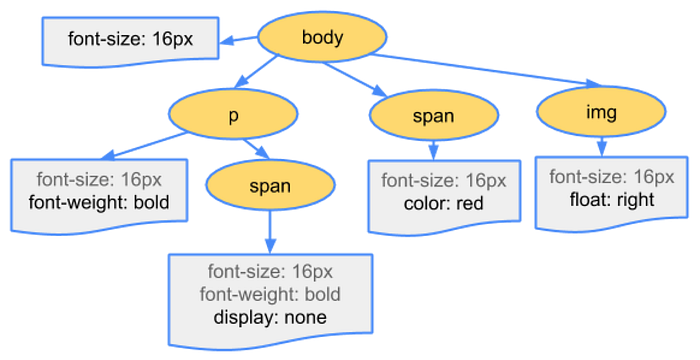
DOM and CSSOM to Render Tree
DOM tree contains the information about HTML element's relationship and the CSSOM tree contains information on how these elements are styled. Starting from the root node the browser traverses each of the visible nodes. Some nodes are hidden (controlled via CSS) and not reflected in the rendered output. For each visible node, the browser matches the appropriate rule defined in CSSOM and finally, these nodes are emitted with their content and styling called Render tree (Layout Tree).
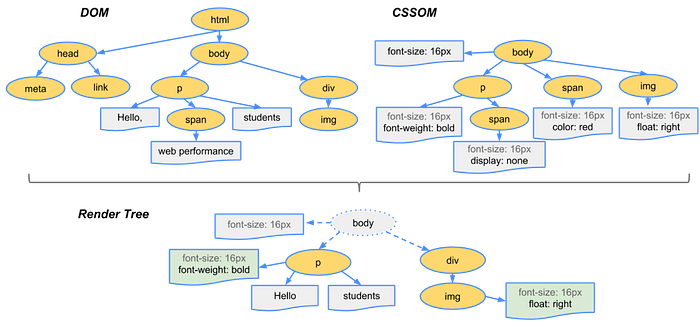
Layout
It then proceeds to the next level called layout. The exact size and position of each of the content should be calculated to render on a page (browser viewport). The process is also referred to as reflow. HTML uses a flow-based layout model, meaning geometry is computed in a single pass most of the time. It is a recursive process starting from the root element (<html>) of the document.
Painting
Each of the renderers is traversed and the paint method is called to display the content on the screen. The painting process can be global (painting the entire tree) or incremental (the render tree validates its rectangle on-screen) and OS generates the paint event on that specific node and the whole tree is not affected. Painting is a gradual process where some parts are parsed and rendered while the process continues with the rest of the items from the network.
For analyzing, measuring, and optimizing the Critical Rendering Path, refer here.
4. JavaScript Interpreter (JS Engine)
JavaScript is a scripting language that allows you to dynamically update the web content, and control multimedia, and animated images executed by the browser’s JS engine. DOM and CSSOM provide an interface to JS which can alter both DOM and CSSOM. Since the browser is unsure what a particular JS will do, it will immediately pause the DOM tree construction after it encounters the script tag. Every script is a parse blocker; the DOM tree construction is halted.
The JS engine begins parsing the code right away after fetching it from the server and feeding it into the JS parser. It converts them into the representative object the machine understands. The object that stores all the parser information in the tree representation of the abstract syntactic structure is called an object syntax tree (AST). The objects are fed into an interpreter which translates those objects into byte code.
These are Just In Time (JITs) compiler meaning JavaScript files downloaded from the server is compiled in real-time on the client’s computer. The interpreter and compiler are combined. The interpreter executes source code almost immediately; the compiler generates machine code which the client system executes directly.
Different Browser uses different JS Engine
- Chrome — V8 (JavaScript engine) (Node JS was built on top of this)
- Mozilla — SpiderMonkey (formerly known as ‘Squirrel Fish’)
- Microsoft Edge — Chakra
- Safari — JavaScriptCore / Nitro WebKit
5. UI Back End
It is used for drawing a basic widget like combo boxes and windows. Underneath it uses operating system user interface methods. It exposes a generic platform that is not platform-specific.
6. Data Storage
This layer is persistent which helps the browser to store data (like cookies, session storage, indexed DB, Web SQL, bookmarks, preferences, etc). The new HTML5 specification describes a database that is a complete database in a web browser.
7. Networking
It handles all kinds of network communication within the browser. It uses a set of communication protocols like HTTP, HTTPS, and FTP while fetching the resource from requested URLs.
Web Browser relies on DNS to resolve the URLs. The records are cached in the browser, OS, router, or ISP. If the requested URL is not cached, the ISP DNS server initiates the DNS query to find the IP of that server. After receiving the correct IP address the browser establishes the connection with the server with protocols. The browser sends the SYN(synchronize) packet to the server asking if it is open for TCP connection. The server responds with ACK(acknowledgment) of the SYN packet using the SYN/ACK packet.
The browser receives a SYN/ACK packet from the server and will acknowledge it by sending an ACK packet. Then TCP connection is established for data communication. Once the connection is established, the data transfer is ready. To transfer the data, the connection must meet the requirements of the HTTP Protocol including connection, messaging, request, and response rules.
Render Blocking and Parser Blocking Resources
Whenever the Browser encounters an element for loading external CSS a request is sent over the network to fetch the .css file asynchronously. It will move immediately (without waiting for CSS resources to be downloaded) to parse elements below it and the DOM construction process is not halted. However, even after DOM tree construction without CSSOM being ready, the Browser won’t render anything onto the screen. To render, both DOM and CSSOM have to be constructed. Hence HTML and CSS are both render-blocking resources. Rendering Content without CSS being fully loaded causes Flash Of Unstyled Content (FOUC).
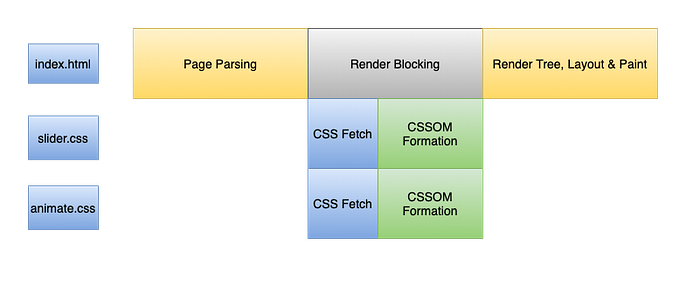
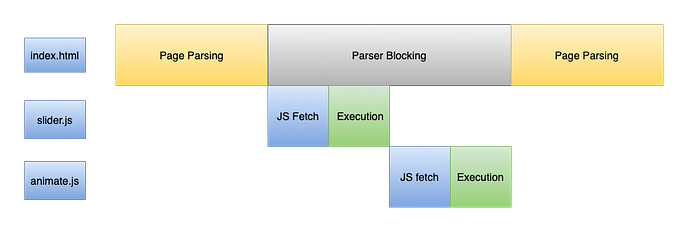
However, that is not the case with Javascript. Whenever the browser encounters a script tag, the DOM construction process is immediately paused until the Js file is downloaded and executed. This is because JavaScript can alter the parsing of subsequent markup (DOM, CSSOM). This makes Javascript a parser-blocking resource.
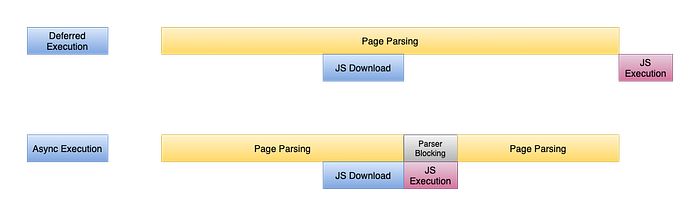
Defer and Async in Script
Both defer and async attributes help the developer to specify the asynchronous mode of Javascript Execution.
Speculative Parsing
As we have seen whenever a script is encountered, parsing is paused. This will introduce a delay in discovering the rest of the resources. In 2008, Microsoft introduced the concept of preloading named “lookahead downloader” followed by Firefox, Chrome, and Safari the same technique under different names. Chrome and Safari have “the preload scanner” and Firefox — the speculative parser.
The basic idea is that discovered files are added to a list and start downloading in the background on parallel connections. The files may be available by the time the script finishes execution. Here the next lightweight parser scans the rest of the markup looking for other required resources. In the case of other Browsers except for Firefox, the contents are preloaded but Firefox (version 4 onwards )goes a step ahead to create a DOM tree speculatively. If speculation succeeds, there is no need to re-parse part of the file constitution DOM. The downside is that if speculation fails, there is more work lost.
Why does the same website look different across Browsers?
Many factors come into play for the discrepancy of the same web pages across different Browsers. Different browsers have different Browser engines (Render Engine and Javascript Engine collectively) that interpret source code (HTML and CSS) in slightly different ways causing this inconsistency. Similarly, the styling of web pages often guided by default settings can lead to the discrepancy as the default settings are different across Browsers.
Other reasons for the disparity include computer settings (screen resolution, color balancing, OS-level differences, fonts), bugs in the engine, and bugs in the web page.
Comparison of Browsers
There are many different web browsers in the market today. Although the primary application of the browser is the same, they differ from each other in more than one aspect. The distinguishing areas are platform(Linux, Windows, Mac, BSD, and other Unix), protocols, graphical user interface (Real, Headless), HTML5, open-source, and proprietary, explained in detail here.
Happy Browsing!!!
References
https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/
https://grosskurth.ca/papers/browser-archevol-20060619.pdf
https://developers.google.com/web/fundamentals/performance/critical-rendering-path/
